




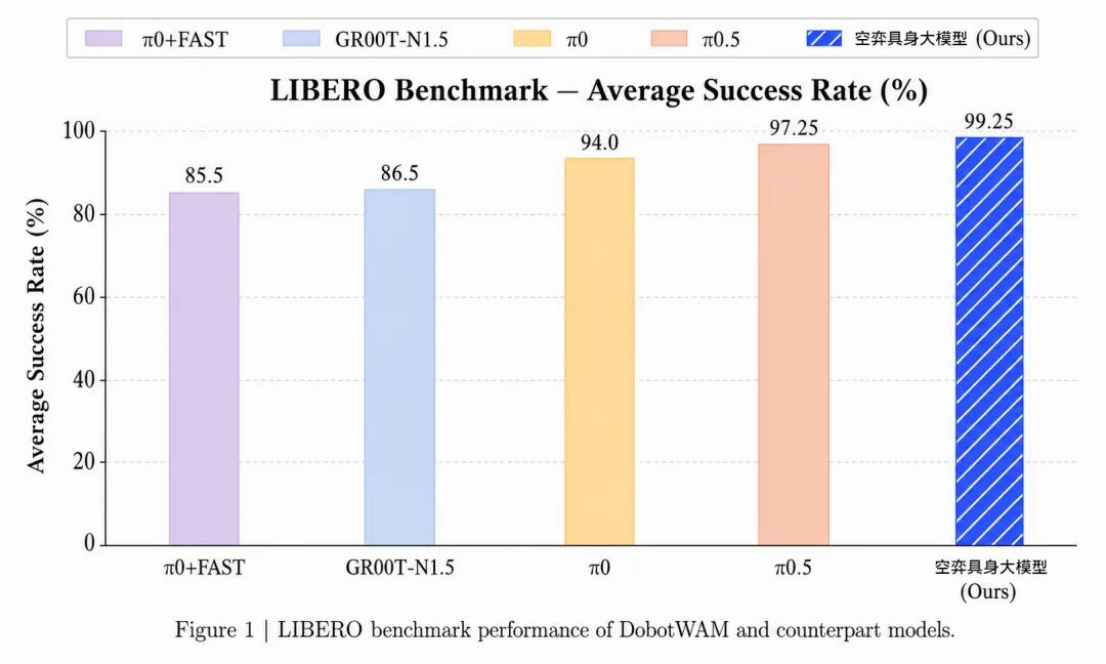
新浪科技讯 6月1日下昼音书老司机午夜精品视频资源,深圳具身智能企业越疆发布自研寰宇动作模子空弈DobotWAM具身大模子,该模子在具身智能模范评测基准LIBERO上远隔完成LIBERO-Spatial、LIBERO-Object、LIBERO-Goal和LIBERO-10四个模范任务套件,掩饰空间联系交融、物体泛化、目标教唆交融以及永劫序任求实施等关键才略维度,平均生效劳达99.25%,进步于π0.5、π0、GR00T-N1.5、π0+FAST等公开模子,以及业内已稀有据公布的其他模子。
其中,空弈DobotWAM具身大模子在LIBERO-Object上终了100/100一起生效,在Spatial、Goal和LIBERO-10三个套件中均达到99/100。
(配图:LIBERO评测撤消)
机器东说念主走向真实利用,简直的挑战不再是“识别物体”,而是在动态、多变的绽放场景中,交融空间联系、拆除名务目标、生成适应通顺结构的动作,并在多步实施中永久保持全局一致。
近两年,乡村欲望视觉-话语-动作模子成为具身智能动作生成的主流范式,在数据掩饰充分、任务范畴赫然的场景下展现了较高后果。关联词,过度依赖二维图像花样或离线轨迹效法,在濒临空间扰动、物体变化、长过程任务和真实战役反当令,仍容易出现动作漂移、目标丢失,或局部动作正确而举座任务失败的情况。这条目机器东说念主模子必须高出单纯的“效法”,日韩美女免费在线确立起对动作深档次结构的简直交融。
据悉,空弈DobotWAM的高生效劳,源于其在感知、交融、为止与数据闭环上的系统性贪图。模子在视觉-话语-动作建模的基础上,进一步引入三维空间交融、机器东说念主通顺几何经管和真实数据闭环机制,使机器东说念主不仅学会“效法动作”,更学会“交融动动作什么这么作念”。
其中枢时间残害包含四个方面:
· 3D-Aware Spatial Representation:将3D空间信息引入视觉-话语-动作建模,使模子不单依赖2D图像纹理和像素特征,偶然显式感知物体位置、空间联系与操作目标之间的几何结构,具备更强的泛化才略。
· Joint Dynamic Geometry Loss:将机器东说念主枢纽动态信息与终局实施器几何经管融入锤真金不怕火loss,使模子从“效法动作”升级为“交融真实动作结构”,从而减少轨迹漂移、姿态不贯串和握取失败,培育永劫序任务中的实施踏实性。
· Advanced VLM Task Decomposition:基于高等VLM backbone对复杂话语教唆进行语义交融与任务拆解,将长过程操作成见为更赫然的阶段目标和可实施子圭表,幸免局部动作正确但全局任务失败。
· High-Quality Data Flywheel + Real-Robot Recap:构建高质料数据飞轮,以Recap真机履行为中枢,闭环集合、锤真金不怕火、评测与反应,连接吸成绩功、失败及长尾场景的真实申饬,培育从仿真benchmark到真实环境实施的迁徙才略。
这四项时间彼此耦合,使得空弈DobotWAM偶然更踏实地完成多物体、多阶段、永劫序的机器东说念主操作任务,为具身智能的大限制落地提供了可复用的系统性框架。(文猛)
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
背负裁剪:孙同怀 老司机午夜精品视频资源